
Si parla sempre di Google, ma in realtà il robot che si occupa del crawl dei nostri siti si chiama Googlebot ed è proprio lui a giocare un ruolo fondamentale nel determinare come il contenuto dei nostri siti sia posizionato nelle SERP di Google.
In poche parole, capire come funziona Googlebot è la chiave di volta per migliorare la visibilità di ogni sito. Vediamo innanzitutto che cosa è Googlebot.
A livello tecnico, si può pensare a Googlebot non come ad un singolo server che scansiona il web, ma per esigenze di scalabilità, a tutto un lavoro che viene distribuito tra diverse macchine sparse per il mondo.
Sostanzialmente si tratta di uno spider che si occupa di scansionare le pagine web su internet con l’obiettivo di trovare nuovi link da visionare e successivamente indicizzare nel database di Google, oltre a verificare periodicamente se siano stati apportati aggiornamenti o modifiche ai contenuti.
Ottimizzazioni rapide del sito per Googlebot
Per agevolare il lavoro di Google durante la scansione del sito, si possono effettuare alcuni interventi non troppo onerosi, ma che possono davvero fare la differenza.
Vediamo immediatamente quali sono gli approcci più interessanti, ma soprattutto efficaci, dato che per una trattazione completa servirebbe probabilmente un libro intero.
Inserisci un file robots.txt con criterio
Nella pratica, il bot cerca di leggere il file robots.txt presente nella root di ogni sito per capire se esistono direttive che impediscono la scansione di specifiche pagine ed è proprio per questo che avere questo file costituisce una best practice in ottica SEO per qualsiasi sito web.
Ad esempio, inserendo nel robots.txt la seguente sintassi, indicheremo a qualsiasi bot (Googlebot, Bingbot, DuckDuckBot, Baiduspider, YandexBot) di non scansionare la pagina privato.html
User-agent: *
Disallow: /privato.html
D’altra parte possiamo anche specificare delle regole per vietare l’accesso solo a determinati bot.
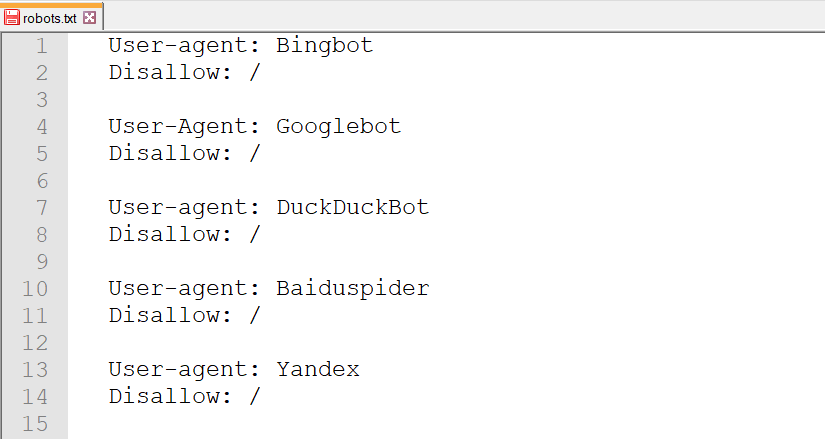
In molti pensano che questa situazione non riguardi il proprio sito, ma è sempre bene verificare se esistano sezioni di poco valore che sprecano risorse del bot (crawl budget), come le aree private, archivi per autore o altro in base al tipo di sito in esame.
In questi casi, potremmo escluderle, facendo concentrare il bot nell’analisi di pagine ben più importanti e ottenendo il risultato di avere un indice di Google aggiornato più frequentemente sulle aree del sito che ci interessano di più.
A questo punto sorgerà spontanea una domanda: è possibile identificare un crawler tra tutte le visite del sito?
La risposta è sì e considerando che ciascuno spider utilizza diversi IP, il metodo di identificazione più sicuro si basa sullo User-Agent, ossia una stringa di riconoscimento.
Banalmente, leggendo i log di Apache potremo trovare righe come la seguente, per scoprire se e quando un determinato crawler è passato sul nostro sito.
11.111.11.111 - - [08/Jul/2019:23:40:23 +0200] "GET / HTTP/1.1" 200 1229 "-" "Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2272.96 Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"
Inserisci una sitemap.xml quando ha senso
Sono stati scritti interi libri sull’importanza della sitemap, ma bisogna sempre contestualizzare.
La mappa del sito svolge una funzione di agevolazione per Googlebot in quanto fornisce la struttura del sito con tutti gli URL che il webmaster ritiene rilevanti.
Senza questo file, il crawler di Big G potrebbe non visitare alcune pagine, magari perché non collegate correttamente da altre sezioni del sito.
Alla luce di queste considerazioni, è evidente che avere una sitemap per un sito vetrina da 5 pagine con link diretti dalla homepage sarebbe assolutamente inutile.
Al contrario, un e-commerce o un blog con contenuti giornalieri farebbe bene a dotarsi di una sitemap.xml e magari anche di una vera e propria mappa del sito HTML visibile dall’utente umano per orientarsi meglio all’interno della struttura del sito stesso.
Bisogna sottolineare che avere o meno questo file .xml non è di per sé motivo di penalizzazione, ma a livello indiretto può portare a minori risultati.
Ottimizza la struttura dei link interni
Ne abbiamo già parlato, ma va sottolineato il fatto che è fondamentale avere un’architettura del sito ben studiata per riuscire a far navigare Googlebot in ogni pagina rilevante del sito.
Nei vari forum di settore, spesso si sente dire che per avere una buona struttura di internal linking, ogni pagina deve essere raggiungibile con al massimo 3 click dalla homepage.
Al di là del numero preciso, è importante notare come pianificare l’architettura del sito sia fondamentale sin dall’inizio, senza lasciare nulla al caso.
In buona sostanza, questo non significa inserire centinaia di link già in homepage, perché poi avremmo una dispersione di link juice, ossia del valore passato da una pagina all’altra.
Al contrario, è un invito all’utilizzo di categorie o comunque ad una distribuzione ragionata dei link in varie sezioni del sito per fare in modo che ogni singolo contenuto abbia un riferimento da altre parti.
Utilizza il tag nofollow con parsimonia
In ottica di preservazione del crawl budget, oltre a lavorare con il file robots.txt, possiamo semplicemente inserire l’attributo “nofollow” ai link presenti nelle pagine, come nell’esempio seguente.
href="http://www.esempio.it/interna.htm" rel="”nofollow”"
In questo modo stiamo dicendo a Googlebot di non scansionare la pagina del link ed eviteremo così uno spreco di risorse. D’altra parte, bisogna fare molta attenzione, perché potremmo avere problemi di indicizzazione parziale nel caso di pagine importanti linkate solo nella pagina di destinazione che abbiamo appena escluso.
Per questo motivo, il rel=”nofollow” va benissimo per link di aree private o sezioni che assolutamente vogliamo escludere dall’indice di Google, ma dobbiamo fare cautela in sezioni di e-commerce o blog, perché potrebbero accadere veri e propri disastri.
Per concludere, nonostante il tema della scansione di un sito web sia spesso sottovalutato, è invece importante intervenire da subito con varie ottimizzazioni per agevolare il lavoro di Googlebot nei confronti del nostro sito.
Infatti, se la SEO OffPage e OnPage sono da sempre le attività privilegiate da chi si occupa di ottimizzazione per i motori di ricerca, d’altra parte, senza avere una scansionabilità ottimale, i risultati del nostro lavoro saranno comunque deficitari.